
June 25th, 2026
VRAM Ghost Busting: Who You Gonna close()?
Léonard Benedetti, Charles Park, Tony Wu (H Company); Kevin Mingtarja (SkyPilot)
TL;DR. Training jobs at H Company kept landing on “idle” GPU nodes that were already holding tens of gigabytes of VRAM, with no owning process to kill. The culprit was a single leaked file descriptor in SkyPilot’s
fusermount-server. After handing/dev/fuseto the user pod viaSCM_RIGHTS, the server kept its own copy of the fd open, so the kernel’s FUSE connection refcount never reached zero and stuck workers inDstate never woke up.The permanent fix is a dozen-line
defer syscall.Close(fd), landed in SkyPilot PR #9463. Older releases can be cleared in place withfusermount -u --abortagainst the stuck FUSE connections; we describe both a manual recipe and a fleet-scale script below.The underlying pattern is not specific to SkyPilot: any privileged daemon that opens a kernel device and hands the fd to an unprivileged peer over
SCM_RIGHTSmust close its own copy afterwards;SCM_RIGHTSduplicates the reference, it does not move it. See Where else this pattern can occur for a few concrete places to look.
Context
At H Company, our training workloads, in particular online RL and large supervised fine-tuning jobs, run on GPU clusters managed by SkyPilot across two backends, as described in our previous blog post: a Kubernetes one (on AWS SageMaker HyperPod, exposing EKS) and a Slurm one. A typical job is a multi-node distributed run on 8xH100 nodes; checkpoints and dataset shards live in S3 and have to be streamed in at high throughput.
SkyPilot’s MOUNT_CACHED is what makes that simple: it exposes an S3 bucket inside the pod as if it were a local directory, with a write-back cache on local disk and rclone mount driving asynchronous sync with the bucket. Training code sees a plain filesystem; under the hood, it is a FUSE mount, with the kernel relaying every filesystem syscall to a userspace daemon.
The bug below lived inside that path. It only ever surfaced on the Kubernetes backend, where SkyPilot uses an additional privileged helper to broker the FUSE mount for unprivileged user pods, but as discussed at the end of the post, the underlying pattern is generic and applies anywhere a similar fd-broker exists.
Initial observation: held VRAM, no owning process
The first sighting was an 8xH100 node that a researcher had freshly booked through SkyPilot. The job OOMed while loading model weights, before training proper had even started. We ran nvidia-smi after the job had crashed and got this:

On a freshly booked node, every GPU should report 0 MiB. Instead GPU 0 had eighty gigabytes pinned, and the seven others were not clean either: each still held between a few hundred MiB and a gigabyte of VRAM it should not have. None of it had a process to attach to or a PID to kill, as if VRAM were being used by a phantom process.
The pre-training Ray bootstrap log from the same node confirmed the picture:
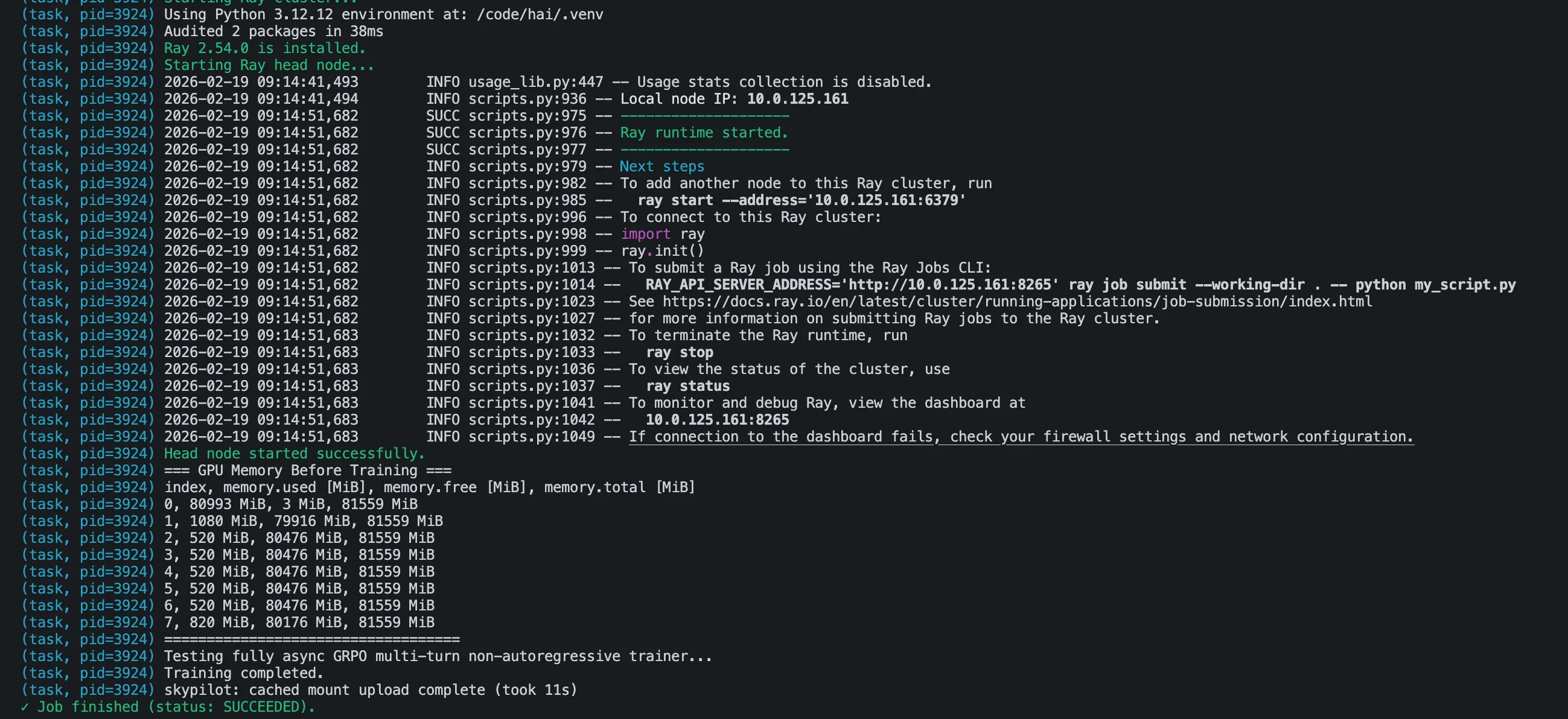
It was not a one-off: over the following weeks the same pattern kept reappearing, nodes that the SkyPilot scheduler considered idle, nvidia-smi reporting tens of gigabytes of allocated VRAM, and no owning process. We s tarted referring to them as “ghost processes” 👻: no PID, no container, no obvious owner.
Diagnosis: tracing the stuck workers back to FUSE
The standard process-level tools (lsof, nvidia-smi, dmesg) all came up empty: from their point of view, nothing was running on the node. We had to drop one layer down, to containerd, and then to the kernel, before anything useful turned up.
Every command below was therefore run on the bare GPU node itself, over AWS SSM Session Manager onto the SageMaker HyperPod instance, not from inside a pod or from a remote workstation. The containerd CLI talks to the host's containerd socket, and the kernel-level surfaces we ended up poking at (/proc/$tid/wchan, /sys/fs/fuse/connections/) only exist in the host’s procfs/sysfs.
Step 1 — Look for containers that should not be there anymore
Even though the Kubernetes API reported no pods on the node, we listed live containerd tasks directly:
Several containers were still in RUNNING even though their pods had been deleted minutes or hours earlier. Pulling the metadata back to the originating pod confirmed they were all SkyPilot job containers:
So whatever was holding the GPU was sitting inside a container that the kubelet had been unable to reap.
Step 2 — Find the threads the kernel cannot wake up
If a container is alive but SIGKILL cannot finish the job, the prime suspect is a process in D-state. D-state corresponds to the Linux TASK_UNINTERRUPTIBLE state, in which a thread is blocked inside a kernel call and ignores signals (including SIGKILL) until that kernel call returns (see this LWN article on TASK_KILLABLE for background). We listed every D-state thread on the node:
This returned 30+ threads, with names like rl-training::Train, pt_nccl_heartbt, cuda-EvtHandlr, pt_elastic, and cuda00001800007, which appeared to have been started in Python:
Those names pointed at CUDA/NCCL stuck inside the NVIDIA driver, exactly the kind of hang you would expect from a half-collapsed distributed training job. Red herring: they were just the thread names the training process had given its workers, not evidence the kernel was stuck inside CUDA. We spent some time pulling on that thread before catching it.
Step 3 — Find the culprit: FUSE
The thing the kernel actually knows about a sleeping task is its wait channel: the symbol of the kernel function it is blocked inside, which is exposed as wchan on Linux (see the proc_pid_wchan(5) man page). For instance:
Hence, we dumped the wait channel for each thread from /proc/$tid/wchan and counted them:
Every single D-state thread was sleeping inside the same kernel function: request_wait_answer. That symbol is defined in fs/fuse/dev.c, i.e. the FUSE device driver. It is the function that parks a thread until the userspace FUSE daemon answers a request (more details about FUSE below). None of this was CUDA, NCCL, or similar: every stuck worker was blocked on a FUSE reply that never arrived.
Concretely the training process was blocked inside a read() on a file that lived behind the FUSE mount, and the answer was never coming.
It also helped that, by the time we got here, we had two distinct sets of affected nodes: one running our rl-training workload and one not, both launched through SkyPilot. This helped further narrow down the scope, as the intersection was SkyPilot and FUSE setup, not the training code.
Step 4 — Confirm from the FUSE side
Every active FUSE mount on a Linux host shows up as a numbered directory under /sys/fs/fuse/connections/, with a waiting file giving (according to documentation):
The number of requests which are waiting to be transferred to
userspace or being processed by the filesystem daemon. If there is
no filesystem activity and ‘waiting’ is non-zero, then the
filesystem is hung or deadlocked.
We listed connections with pending waiters:
The number of pending waiters across connections matched the D-state thread count exactly. The kernel was holding live FUSE connections, with no userspace daemon on the other end answering them.
But this is not how FUSE is supposed to behave: when the userspace daemon dies, the kernel is meant to abort all pending requests so that blocked readers wake up with -ECONNABORTED. The function that does this is fuse_abort_conn, and it was clearly not called for these connections.
Step 5 — Verify by forcing the connection closed
The FUSE control filesystem exposes an abort file per connection that forces the kernel to tear it down regardless of who still holds a file descriptor (“fd”) onto it. On a cordoned, otherwise-idle test node, we aborted the stuck connections:
The blocked workers exited within seconds, and nvidia-smi immediately reported the GPUs as free. That closed the loop on the mechanism: stuck FUSE connections were keeping training processes parked in request_wait_answer, which kept them holding their CUDA contexts, which is why the VRAM never came back.
What was not yet clear was: (a) why the userspace FUSE daemon died, and (b) why fuse_abort_conn had failed to fire on its own once the FUSE daemon died (which is what should normally short-circuit that chain by waking the parked read() with -ECONNABORTED).
Detection checklist
To recap, here are the five signals from steps 1–5 above, condensed into a single checklist you can run on another fleet:
Held VRAM on an idle GPU node with no owning process:
nvidia-smiContainers stuck in
RUNNINGafter their pods are deleted:ctr --namespace k8s.io tasks listD-state threads sleeping in
request_wait_answer:cat /proc/$tid/wchanfor eachtidfromps -eLo state,tid | awk '$1 ~ /D/'FUSE connections with pending waiters and no userspace daemon:
cat /sys/fs/fuse/connections/*/waiting/dev/fusefds accumulating infusermount-serveracross mounts:kubectl exec -n skypilot-system <fusermount-server-pod> -- sh -c 'ls -l /proc/1/fd | grep -c fuse'
A first Quick-and-Dirty™ hotfix: aborting stuck FUSE connections at fleet scale
While the investigation continued, we needed the fleet to stop poisoning new jobs. The Step 5 abort recipe worked node-by-node; we wrapped it in a small script (kill_zombies_k8s, at this point, the ghosts had turned into zombies in our minds 🎃) that targeted idle GPU nodes on our SageMaker HyperPod cluster, probed each one for held VRAM with an nvidia-smi pod, and ran fusermount -u --abort on the ghost processes through AWS SSM.

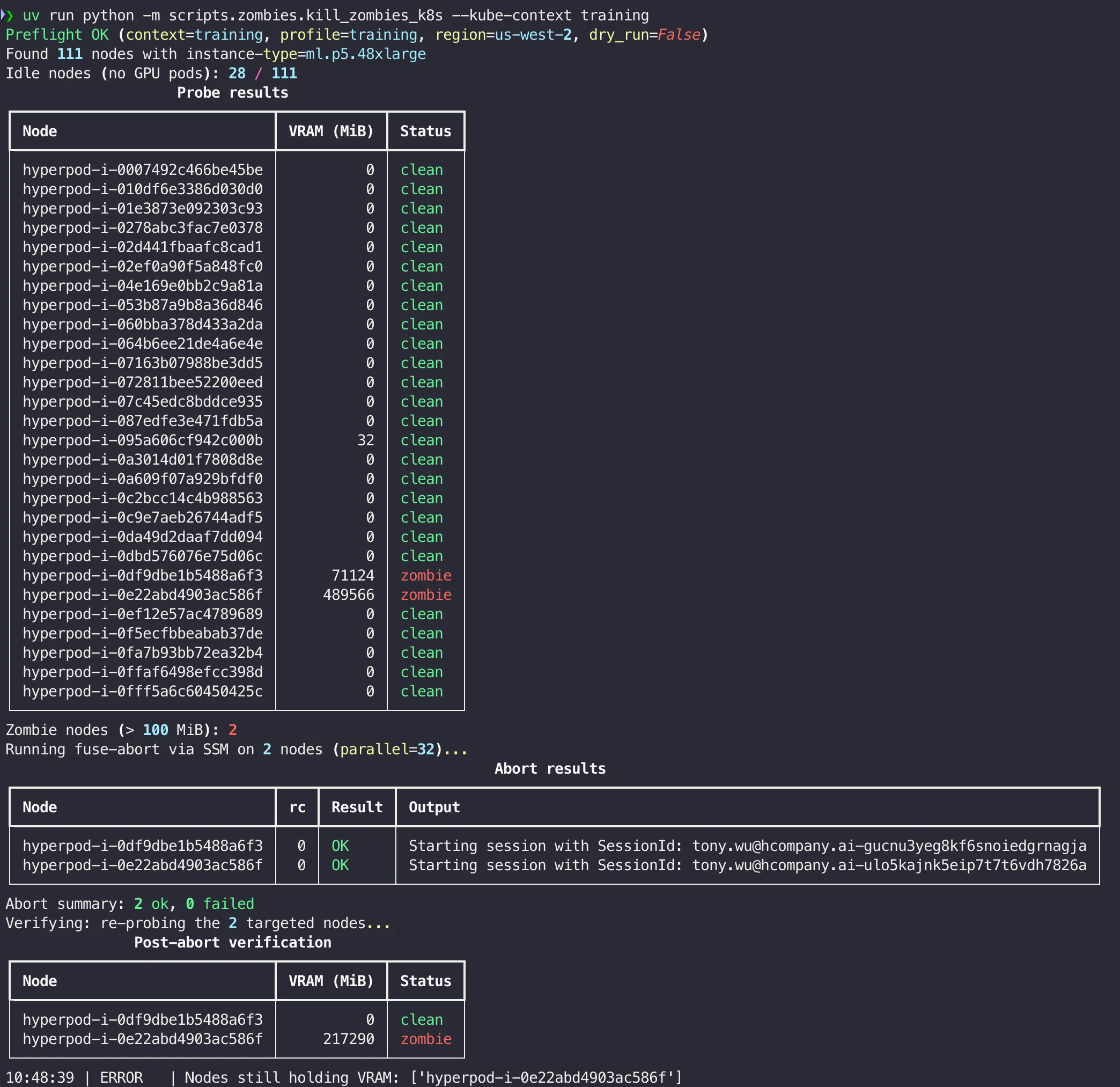
The abort cleared most ghost processes on the spot. A few stubborn nodes kept their VRAM even after the kernel-level abort and required a reboot. That asymmetry was a clue we did not fully appreciate at the time; we’ll come back to it once the root cause is in view.
The hotfix gave researchers their cluster back. It did not tell us why the leak existed in the first place.
MOUNT_CACHED and the FUSE plumbing underneath
To explain why the kernel was holding live FUSE connections with no userspace daemon, we need to sketch the storage path that produced them and to explain how FUSE works.
SkyPilot’s MOUNT_CACHED exposes, using rclone mount, an S3 bucket to a job as a local directory with a local VFS cache layered on top: reads are served from cache when possible, and writes hit local disk first and are asynchronously uploaded to the bucket. That is what makes it usable for our checkpoints: training writes at local-disk speed instead of waiting on S3 round-trips.
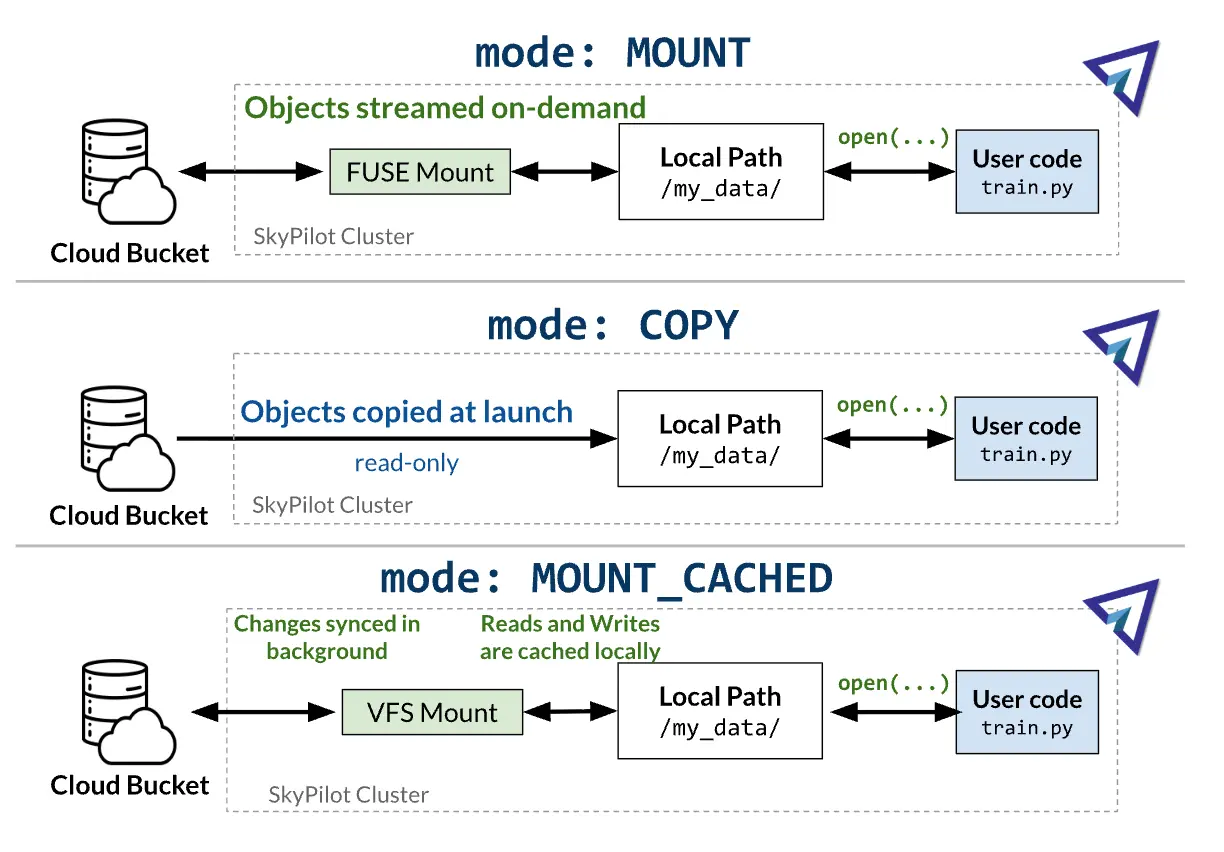
Under the hood it is a FUSE mount. The kernel docs describes it this way:
FUSE is a userspace filesystem framework. It consists of a kernel module (fuse.ko), a userspace library (libfuse.*) and a mount utility (fusermount).
A FUSE mount has two halves wired together by a single open fd onto /dev/fuse. The kernel side receives every filesystem syscall against the mount point (e.g. read("/mnt/myfs/foo")) and serializes it as a request (FUSE_READ) onto that fd; the userspace daemon reads requests from the fd onto /dev/fuse and writes back answers. In MOUNT_CACHED’s case that daemon is rclone mount, which serves reads from the local cache and reconciles with S3 in the background.
Why the userspace FUSE daemon died
This was the easiest question to answer: the rclone mount daemon was killed for OOM under heavy parallel reads. With vfs_read_chunk_size: 32M and vfs_read_chunk_streams: 16 it shares the main container’s memory budget with the training process, so a memory spike on the training side could evict it. That answers (a) but not (b): even after rclone was gone, the kernel kept parking read()s on the mount point instead of aborting them with -ECONNABORTED.
If you are picking up MOUNT_CACHED for production training, SkyPilot’s cache-tuning guide is the natural next read: it walks through these vfs_* chunk knobs and the local-disk cache sizing in detail.
How the kernel decides to abort a FUSE connection
A few consequences of FUSE’s design matter for the bug:
The lifetime of the FUSE mount is bound to the
/dev/fusefile description, not to any client process (i.e. a process that performs filesystem operations, likeread(), on a FUSE-mounted directory). The kernel reference-counts how many fds across the system still point at it (dev_count, internally). Normally, only the userspace FUSE daemon holds an fd on/dev/fuse, and processes that only use a FUSE connection don’t.The teardown function,
fuse_abort_conn, only fires whendev_countreaches zero. As long as any process, anywhere, still holds an open fd onto/dev/fusefor that mount, the kernel will keep parking new requests on it and waiting for an answer.If the userspace daemon dies but some other fd onto the same
/dev/fuseis still open, pending requests stay parked. That is the state we kept finding on stuck nodes.
What remained was to explain who else was holding an fd onto /dev/fuse after rclone died.
Early hypotheses that didn’t hold up
Before the real cause surfaced, we chased two reasonable but wrong leads.
The first hypothesis was a container shutdown ordering issue. Our guess was a lifecycle race: workers killed after rclone, so the daemon was already gone by the time they tried to read. We reproduced this on a SageMaker AL2023 setup (kernel 6.1.159-182.297.amzn2023.x86_64, NVIDIA driver 580.126.09) and tried moving rclone mount into a Kubernetes sidecar container, so the FUSE daemon’s lifecycle could be ordered relative to the main container’s.
The sidecar version worked, but it had three problems we flagged in the thread:
The sidecar had to run
privileged: trueand usemountPropagation: Bidirectionalfor the mount to be visible inside the main container.Resource accounting got messy. Until then
rcloneinherited the main container’s CPU and memory limits. As a separate sidecar it needed its own. With ourvfs_read_chunk_size: 32Mandvfs_read_chunk_streams: 16settings,rclonewas already memory-hungry under load, and a tight sidecar limit risked OOM-killing the daemon.MOUNT_CACHEDis not a Kubernetes-only feature, but sidecars are. The fix would not generalize to the cloud-VM path.
The second hypothesis was a preStop hook. If the worker could be terminated before rclone, we would dodge the race entirely. Use Kubernetes’s lifecycle.preStop to force the worker down (or fusermount -u the mount) before pod teardown gets to rclone. We never built it: the breakthrough below arrived first, and once we understood the real refcount problem it was clear preStop would only have masked it on the happy path. A worker that already had a read() parked in request_wait_answer could not be cleanly torn down by a hook anyway.
Both hypotheses correctly identified that something about lifecycle ordering matters. They were wrong about why. The kernel does not actually need any specific shutdown order to release a FUSE connection, as long as the /dev/fuse reference count drops to zero, fuse_abort_conn fires and pending requests get aborted. What mattered was that one of those references was never going to be released at all.
A related dead end: for a while we suspected the leftover fusermount-server daemon process on the node, simply because it was the FUSE-adjacent thing that was still visibly running once the user pod had been torn down. By contrast, the rclone mount process from the dead pod was already cleaned up by the time we looked. That visibility bias sent us looking at the wrong process; the leak was inside fusermount-server, but for a non-obvious reason.
Root cause: an SCM_RIGHTS duplicate that was never closed
A short detour into file descriptor mechanics: a file descriptor is a per-process integer that points to a kernel object. Multiple fds in the same or different processes can refer to the same object. The kernel reference-counts them and only tears the object down when the last fd is closed. When you pass an fd over a Unix socket using SCM_RIGHTS, the kernel does not move the reference. It duplicates it. The unix(7) man page is explicit about this:
Commonly, this operation is referred to as “passing a file descriptor” to another process. However, more accurately, what is being passed is a reference to an open file description (see open(2)), and in the receiving process it is likely that a different file descriptor number will be used. Semantically, this operation is equivalent to duplicating (dup(2)) a file descriptor into the file descriptor table of another process.
It is the same kind of reference counting Python uses to free an object the moment its last reference drops to zero. Both the sender and the receiver end up with their own fd onto the same underlying open file description. For /dev/fuse, as described above, the kernel tracks this count in a field called dev_count on the FUSE connection, and fuse_abort_conn only fires when dev_count hits zero.
The other piece is how SkyPilot mounts FUSE on Kubernetes. Mounting FUSE there normally requires a privileged container, since mount(2) is a privileged syscall and /dev/fuse is a host device. To keep user pods unprivileged, SkyPilot ships fusermount-server, a per-node DaemonSet that does the privileged work on behalf of unprivileged pods. The user pod talks to it over a Unix domain socket; the server opens /dev/fuse, calls mount(2), and hands the file descriptor back via SCM_RIGHTS.
After the handoff, fusermount-server has nothing more to do for that mount. The user pod’s rclone services FS requests; the server walks away.
While prototyping the sidecar fix, we started counting open /dev/fuse fds inside the fusermount-server pod, expecting them to drop to zero between mounts, but they did not. Each successful mount left one behind:
Seventeen file descriptors were still there, on a node that currently had one active SkyPilot cluster. This confirmed that the fusermount-server was not closing the /dev/fuse fd after sending it to the client, so even after rclone died and released its own fd, the kernel still saw an outstanding reference and could not tear down the FUSE connection.
Hence, the seventeen we counted were accumulated connection leftovers: fusermount-server runs as a long-lived per-node DaemonSet, so each successful mount it had served over its lifetime, across every SkyPilot cluster that had come and gone on this node, left one fd behind, never closed. I.e. 17 separate FUSE connections, all stuck with a dev_count = 1.
In refcount terms:
Both prior hypotheses had quietly assumed that, in a healthy run, only rclone ever held the /dev/fuse fd; since, as mentioned above, in a typical FUSE setup, only the userspace FUSE daemon holds an fd for /dev/fuse. But actually, the server was also holding a valid duplicate from the moment it sent the original. No matter how cleanly we shut things down on the user side, the kernel saw a refcount stuck at one because of these duplicates, since the server never closed these fds, which remained valid. This prevented FUSE connections from being aborted, resulting in ghost processes, which finally answers question (b).
It also explained why fusermount -u --abort was such a reliable hotfix: the abort path forces the kernel connection closed regardless of who else still holds an fd onto it.
It accounts for the stubborn nodes too, partially. On those nodes, the abort did unwedge the workers (the FUSE connection went away), but the workers had been parked for hours by then, and the NVIDIA driver could no longer reclaim their CUDA contexts cleanly. Aborting frees the kernel’s FUSE state; it does not undo whatever the driver had done to the GPU side in the meantime. For the worst-aged ghost processes, a reboot was the only path back.
The fix
A dozen lines of Go in SkyPilot’s FUSE proxy (addons/fuse-proxy/pkg/server/server.go) (SkyPilot PR #9463): after SendMsg hands the fd to the client, the server defers a syscall.Close(fd) on its own copy.
Two design choices in that snippet:
deferis used rather than callingcloseimmediately because the receiver’s duplicate only exists onceSendMsgsucceeds. Closing beforeSendMsgcould let the kernel tear down the underlying object before the send completed.deferregisters the cleanup now and lets it fire afterSendMsgreturns, regardless of how the function exits.The
fd > 0guard exists because the same handler also serves unmount requests, where there is no fd to hand back andfdis set to0as a sentinel. The deferred close should only fire on the mount path.
Order of operations on a successful mount, after the fix:
Step 5 is the one we were missing.

Conclusion and takeaways
A bug that presented as held VRAM on idle GPU nodes turned out, twelve lines of Go later, to be a single missing close() in a privileged DaemonSet. Getting from one to the other took us through nvidia-smi, containerd, the kernel’s D-state machinery, the FUSE control filesystem, and the semantics of SCM_RIGHTS; none of which were obviously connected at the start. A few lessons we are taking with us:
SCM_RIGHTSduplicates; it does not move. Every code path that passes an fd over a Unix socket has to explicitly decide whether the sender keeps its copy. The Go socket APIs will not close it for you.When
wchannames a kernel function, trust it.wchantold us the answer was inside FUSE on day one. The worker thread names (rl-training::Train,cuda-EvtHandlr, …) sent us chasing CUDA and NCCL for a while; the kernel symbol the kernel itself reported was much more accurate.Fixes that work for the wrong reason can stall the real one. The sidecar prototype and our
fuse-aborthotfix both made the symptom go away. They were correct workarounds, but each one made the underlying leak a little less urgent to find.
The fix has been running in production at H Company since PR #9463 landed, and we have not seen a ghost process since.
Where else this pattern can occur
The bug is not specific to SkyPilot, nor even to MOUNT_CACHED. It is a generic hazard for any privileged broker that opens a kernel device and hands the resulting fd to an unprivileged peer over a Unix socket. For FUSE alone, the same issue could, for instance, show up in any in-house DaemonSet or systemd unit that re-implements an unprivileged-mount pattern similar to SkyPilot’s.
The issue generalizes beyond FUSE too. For instance, the same refcount trap exists for /dev/kvm in rootless VM monitors (e.g. Firecracker, Cloud Hypervisor), /dev/net/tun and /dev/vhost-net in rootless networking and CNI plugins, and the various device fds passed across by Wayland compositors. In each case, the kernel object behind the fd is reference-counted, and a broker that fails to close its own copy after handing one to a peer will pin the object indefinitely, manifesting downstream as whatever that object happens to anchor (a stuck mount, a VM that won’t die, a tun device that won’t go away, etc.).
The rule, regardless of device, is the one unix(7) already tells us: if you send a file descriptor via SCM_RIGHTS, you almost always also need to close() your own copy afterwards. Go’s unix.Sendmsg is a particularly easy place to get this wrong, because the file descriptor is just a plain int, there is no *os.File wrapper whose finalizer would clean it up for you. Rust’s OwnedFd / BorrowedFd types in std::os::fd are designed precisely to make this mistake harder.
If you operate your own FUSE-based storage layer, e.g. rclone, s3fs, gcsfuse, goofys, gocryptfs, or a custom passthrough mount, and a privileged helper is involved in the mount path, the diagnostic recipe in this post (D-state → wchan → /sys/fs/fuse/connections/*/waiting → controlled abort) should transfer directly. The exact downstream symptom may differ from “stuck VRAM” depending on what your application happens to be doing when the FUSE daemon dies, but the root mechanism is the same: a FUSE connection the kernel cannot tear down because of a leaked refcount.
Acknowledgments
This investigation was a joint effort between H Company (Léonard Benedetti, Charles Park, Tony Wu) and SkyPilot (Kevin Mingtarja). The fix lives in SkyPilot PR #9463 and ships in the fusermount-server:0.2.2 image, which now benefits everyone running MOUNT_CACHED on Kubernetes.