
SkyPilot
March 24, 2026
Unlocking Online RL and Unifying Our AI Platform Across Kubernetes and Slurm
TL;DR: H Company unified Slurm and Kubernetes with SkyPilot into a single interface for training, enabling scalable workflows and bringing online reinforcement learning into production.
H Company has 30+ researchers focused on advancing agentic model capabilities for computer use through large-scale training and reinforcement learning. We operate 2,000+ GPUs across two cloud providers, supporting everything from supervised fine-tuning to complex online RL pipelines.
As this work scaled in both complexity and ambition, our infrastructure had to evolve alongside it. Supporting a growing number of experiments, larger models, and more demanding training workflows, we needed systems that could:
Support both traditional training workflows (SFT, DPO, GRPO) and cutting-edge online RL
Bridge training infrastructure with K8s-based inference services (custom vLLM)
Give researchers a familiar, Slurm-like experience while leveraging modern K8s orchestration
Maintain high GPU utilization across our multi-cloud setup
Speed up saving terabytes of checkpoints to S3
Building infrastructure that checks all these boxes with a lean team is challenging. This blog post illustrates how we leveraged SkyPilot to build a lean, multi-cloud orchestration layer that solves these challenges and accelerates our agentic research.
The Challenges of Scaling Our Training Infrastructure
Online RL required Kubernetes, but H Company’s existing workflows were optimized around Slurm
Slurm had been our workhorse for traditional training. SFT, DPO, GRPO – all of it ran well on Slurm clusters, and our researchers were comfortable in that environment.
On the other hand, online RL requires the trainer to interact with custom vLLM inference servers for both generation and weight synchronization across GPUs. These are long-running, service-style components that fit naturally on Kubernetes, whereas Slurm is designed for batch jobs and is not optimized for this kind of tight integration.
“Slurm worked fine for SFT. However, to support online RL, we had to run the trainer on K8s so it could communicate with our custom vLLM inference server.” — Tony Wu, Core Researcher Engineer at H Company
The challenge is that moving training to Kubernetes introduces additional operational overhead for training workflows.
K8s abstractions are not optimized for iterative ML experimentation
K8s deployment manifests introduced additional configuration surface area (managing Docker images, networking, service discovery, topology), increasing operational overhead compared to batch schedulers. This also resulted in duplicated configuration across Slurm and K8s environments, and researchers ended up maintaining both a K8s deployment file and a Slurm batch script to describe the same training logic.
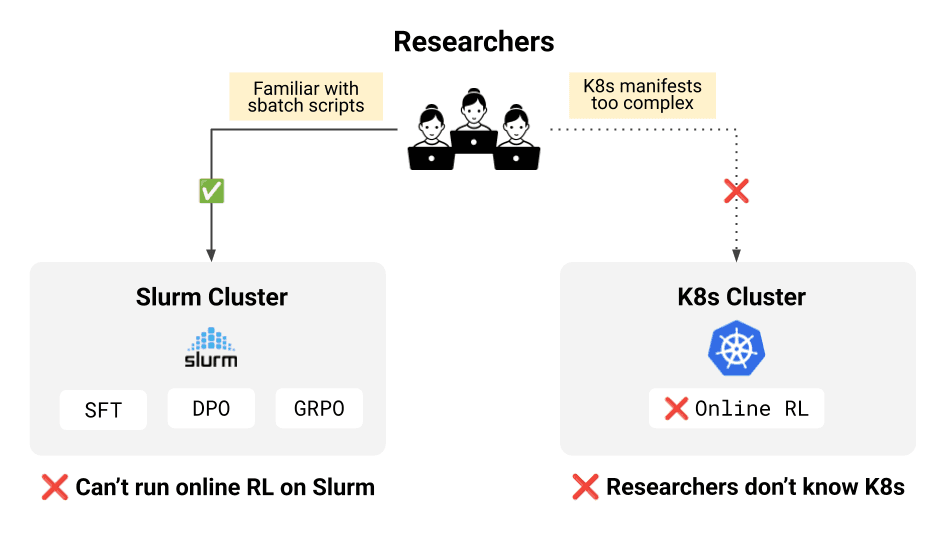
Slurm lacked primitives for modern research workflows
On the Slurm side, we originally implemented checkpoint-triggered evaluation via custom scripts, but this approach lacked native scheduling support, observability, and failure handling.
How SkyPilot Powers Our AI Research
One interface for both Kubernetes and Slurm
SkyPilot provides a single interface that works seamlessly across both K8s and Slurm clusters. Researchers use one command (sky launch or sky jobs launch) regardless of where the job runs. No deployment manifests, no pod configurations, no switching mental models between environments.
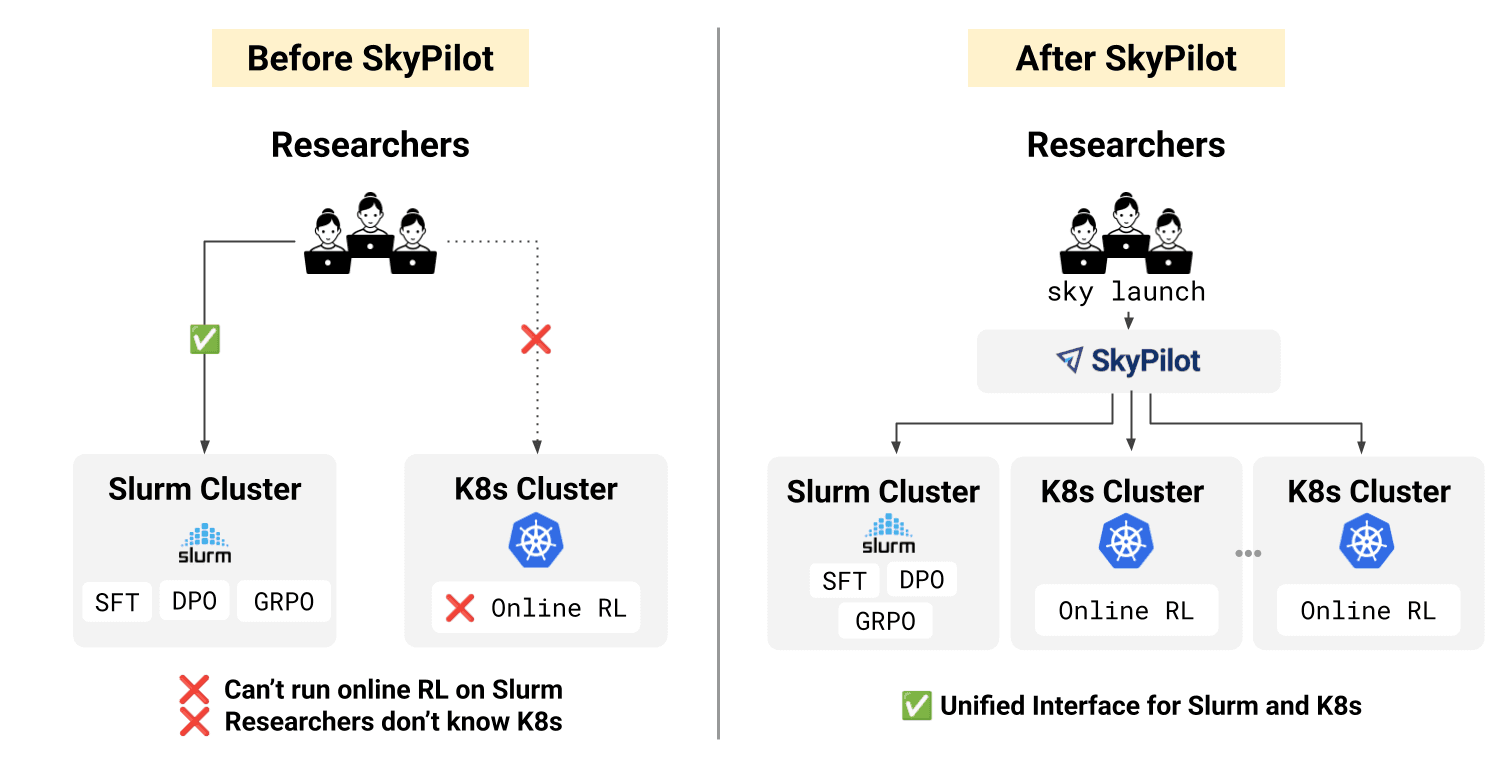
SkyPilot abstracts cluster-specific details, allowing training workflows to remain infrastructure-agnostic. Researchers keep writing standard training code using familiar frameworks like PyTorch distributed, Ray, veRL, and Megatron as SkyPilot abstracts the orchestration complexity away.
Complex training workflows made easy
SkyPilot can handle multi-node distributed training and parallel workflows natively.
Automatic multi-node orchestration: SkyPilot provisions nodes, sets up networking, and populates environment variables (
SKYPILOT_NODE_IPS,SKYPILOT_NUM_NODES, etc.), so distributed frameworks can discover cluster topology automatically.Works with any framework: Any PyTorch distributed code (torchrun), Ray, veRL, Megatron: all work out of the box.
JobGroups for parallel train/eval: Define training and evaluation as separate jobs that run concurrently, sharing storage for checkpoints. Training is the primary task; eval watchers are auxiliary and auto-terminate when training completes.
CPU-only watchers: Eval watchers spawn GPU jobs on-demand, keeping watchers CPU-only to free GPU resources.
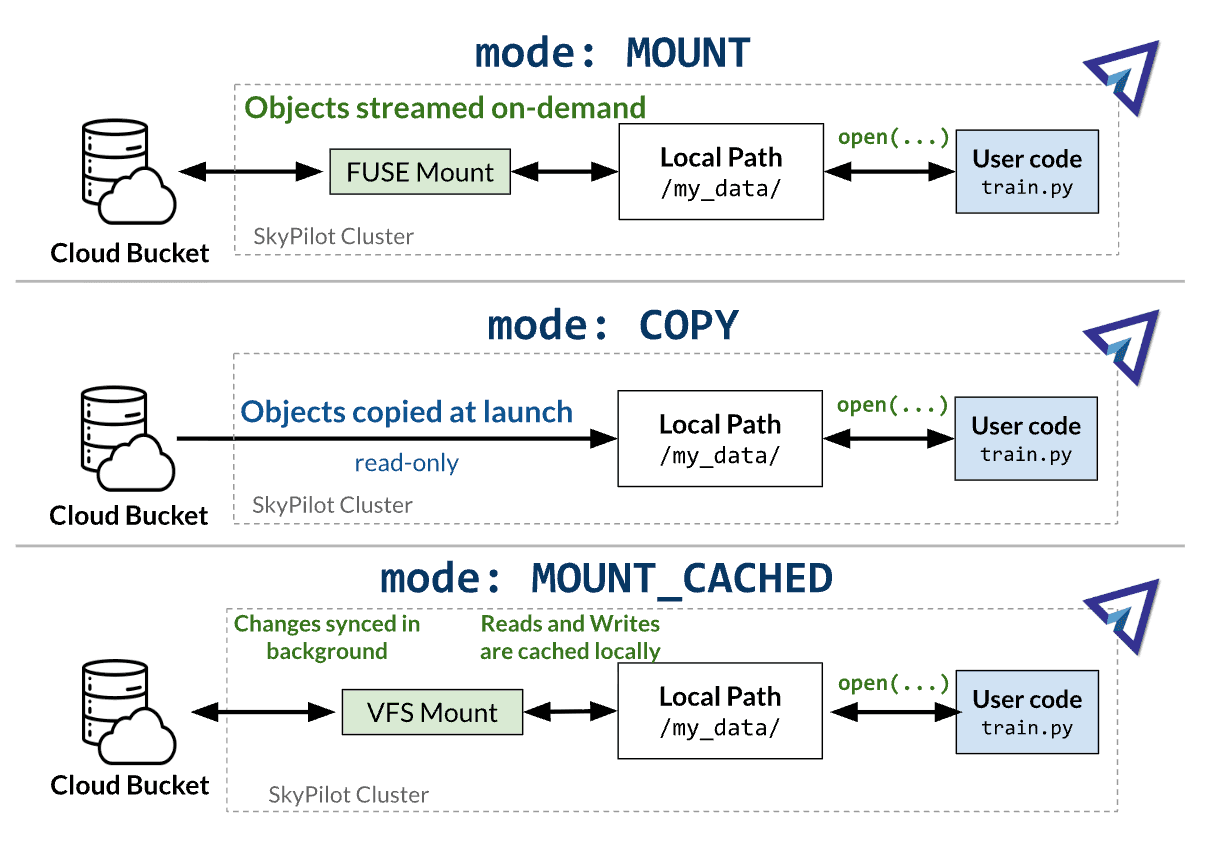
Checkpointing with MOUNT_CACHED: Training writes checkpoints at local SSD speed (GBps) instead of FUSE S3 speed (typically MBps). This saves even more time when training models up to the 200-400B parameters as saved checkpoints (parameters + optimizer states) can weigh more than 1TB each.
Here's what a typical Job Group looks like:
Scaling SkyPilot to the entire team
We rolled this out incrementally until adoption extended across the entire research team.
Unified dashboard for all users: Single dashboard shows all jobs across all users, improving transparency and resource visibility. Users can see who's running what and coordinate with each other.
Self-service migration: Researchers successfully migrated their own training scripts from Slurm to SkyPilot in about an hour without needing infrastructure team support, thanks to straightforward YAML configuration.
Easy auth with SSO: Deployed on K8s with Helm, providing centralized job management and authentication via Google SSO.
Growing adoption: Started with one user, quickly grew to the entire research team.
Regression tests on SkyPilot: Regression tests were migrated from custom shell scripts that would SSH to the cluster to SkyPilot jobs, improving observability, reproducibility, and failure handling. Tests now run as first-class jobs with centralized logging, status tracking, and automatic retries, improving the training stack’s robustness and maintainability.
Results: Online RL Unlocked, Simpler Infrastructure, Better Utilization
SkyPilot is now our standard AI infrastructure layer, powering all our training.
Enabling Online RL. Complex RL workflows requiring communication between training jobs and custom vLLM inference servers now run seamlessly on Kubernetes.
Improved GPU utilization. SkyPilot's fault tolerance and priority scheduling keep GPUs busy by auto-recovering failed jobs and prioritizing high-value workloads, minimizing idle time across our clusters.
Team adoption in weeks. What began with a single user scaled to the entire research team, with all training workflows running through SkyPilot across both Kubernetes and Slurm, and across cloud providers. Researchers migrated their workloads independently, without requiring infrastructure team support.
Unblocking AI research. Our researchers can now change CUDA runtime, NCCL library, and EFA-like driver versions directly in a Docker image instead of waiting on the cloud provider for updates. This eliminates dependency on vendor timelines and avoids the need for privileged access to manage the stack.
Most importantly, SkyPilot allows us to standardize infrastructure access behind a single interface, so research workflows remain consistent as our systems scale.