
April 28th, 2026
H Company is proud to introduce Holotron 3 Nano (30B A3B), our latest multimodal model designed for automated computer tasks. We built this version by post-training NVIDIA’s Nemotron 3 Nano Omni on our proprietary data mixture to enhance agent policy modeling.
This release delivers Mixture-of-Experts (MoE) capacity, a more powerful vision encoder, and native long-context support. Crucially, Holotron 3 Nano introduces these capabilities while retaining the high inference throughput that made Holotron-12B so effective for production-scale use.
Key Improvements & Availability
Reduced Latency: Compared to Holo3 Flash, this model significantly reduces latency, enabling more responsive real-time agentic workflows.
Try it in HoloTab: You can experience the model's capabilities firsthand in HoloTab, our browser-based AI agent platform.
Open Access: The model is available on Hugging Face under the NVIDIA Open Model License.
H Company is part of the NVIDIA Inception Program.
Why We Built Holotron 3 Nano
Holotron 3 Nano continues the legacy of Holotron-12B as a specialized policy model for agents that perceive and act within interactive environments. By outperforming other leading models like GPT-5.4 and Sonnet 4.6 at a lower price point, the Holotron 3 Nano model is Pareto-optimal in terms of price-performance.
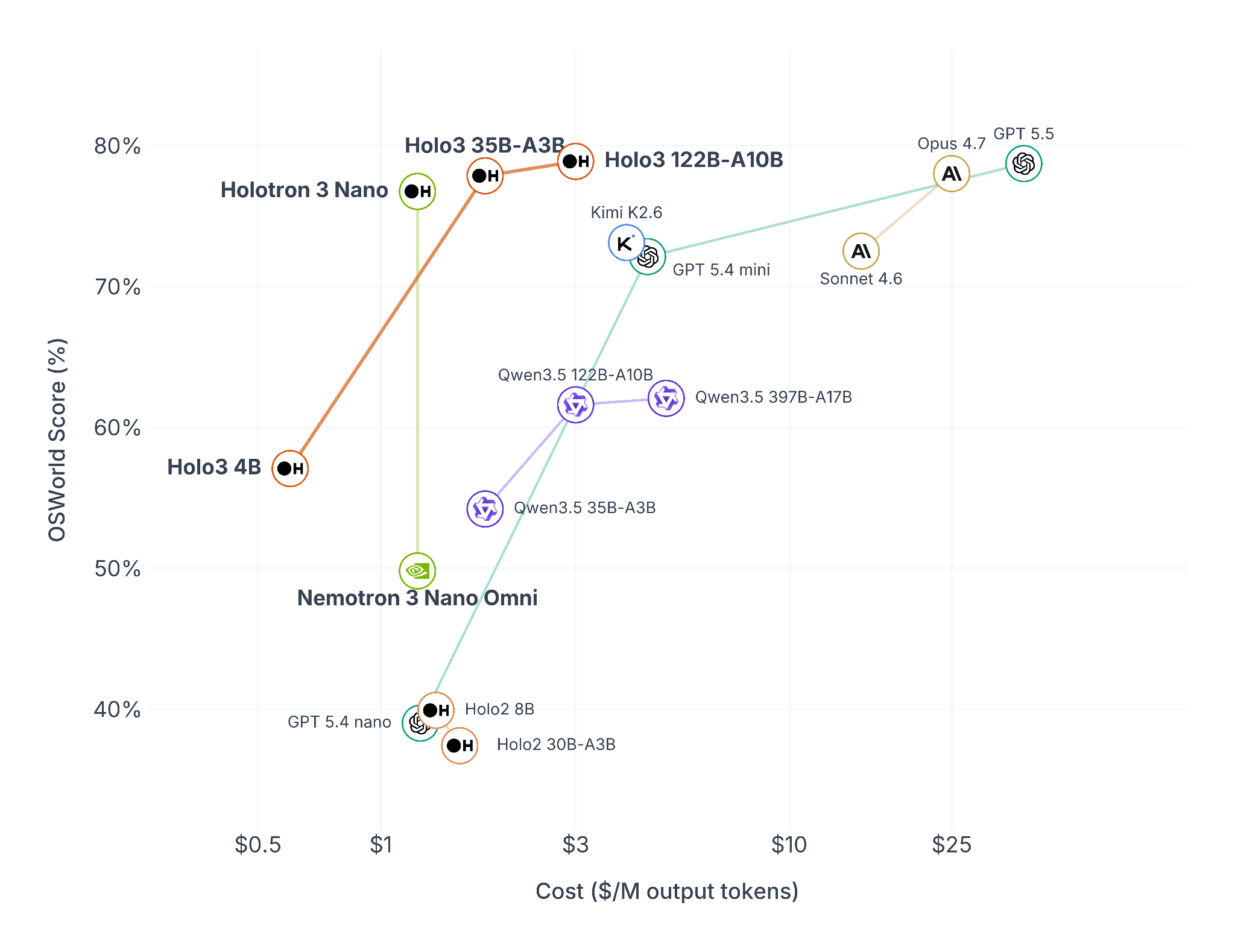
Architectural Upgrades: Sparse Hybrid MoE & Optimized Vision
Holotron 3 Nano utilizes a Sparse Mixture-of-Experts (MoE) design to scale its knowledge base without increasing computational overhead. Built on the Nemotron 3 Nano recipe, the architecture interleaves Mamba-2 layers for constant-memory sequence modeling, Sparse MoE layers that activate only 3B out of 30B parameters per token, and selective self-attention to enable a 256K token context window.
On the perception side, Holotron 3 Nano integrates C-RADIOv4, which distills DINOv3, SigLIP2, and SAM3 into a single, high-performance student architecture. It introduces any-resolution support and ViTDet "windowed attention" to process diverse, high-resolution screen captures efficiently. By matching the grounding quality of 7B-parameter models at a fraction of the cost, C-RADIOv4 provides the high-fidelity perception required for complex agent workloads.

Training and Evaluating Holotron 3 Nano
We trained Holotron 3 Nano using FSDP combined with Expert Parallelism (EP) across 16 nodes (128 H100 GPUs). The final checkpoint was trained on approximately 3,000 H100-hours on the proprietary data mixture, resulting in 52 billion tokens seen during training.
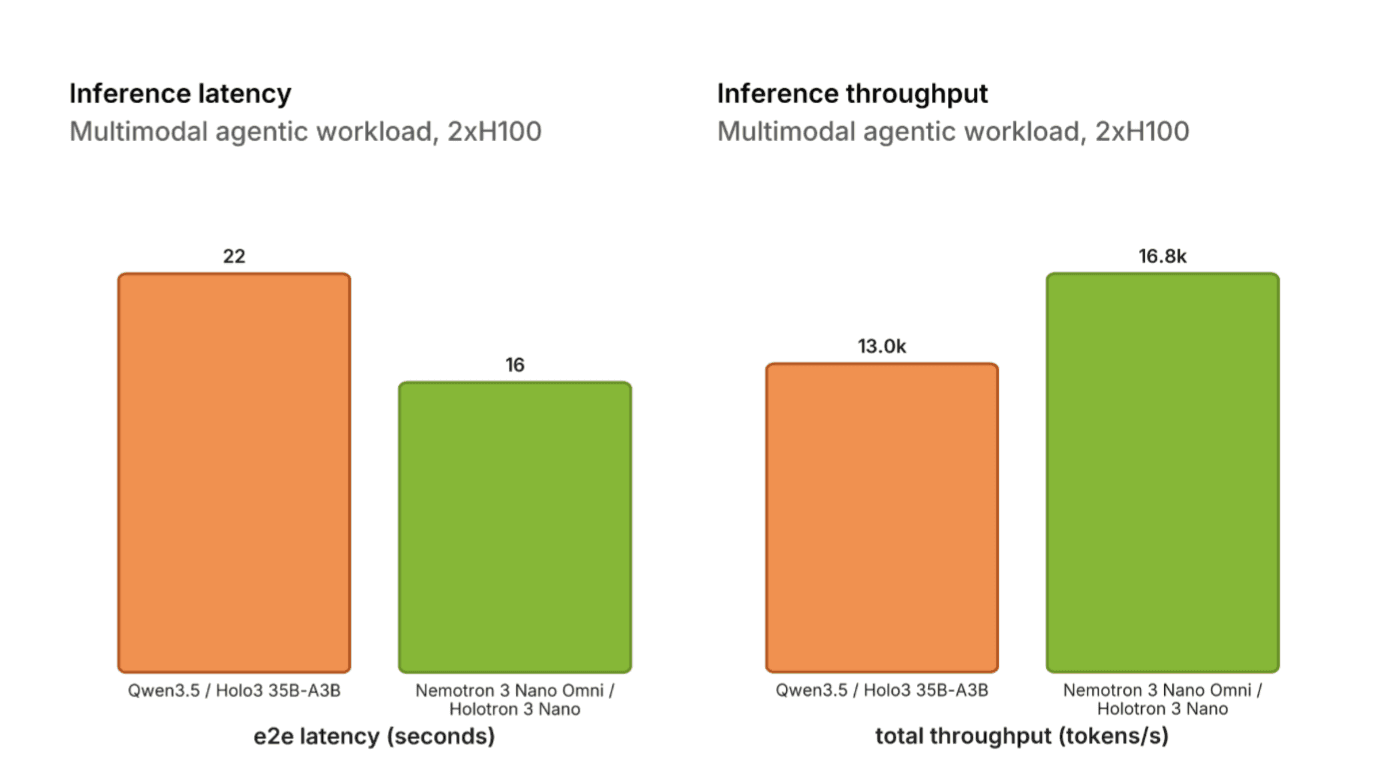
Inference Throughput
Benchmarked on 2xH100 using the official vLLM benchmark script, Holotron 3 Nano achieves approximately ~30% higher token throughput than Holo3 and ~27% lower end-to-end latency (with 10 concurrent requests) for the agentic CUA workload. This is especially impressive as Holo3 is based on Qwen3.5, which is a hybrid architecture as well.
Agent and Localization Benchmarks
Holotron 3 Nano shows consistent gains over the Nemotron 3 Nano Omni across computer-use, enterprise workflows, and UI grounding benchmarks. It is particularly effective in real-world execution and multi-step interactions.
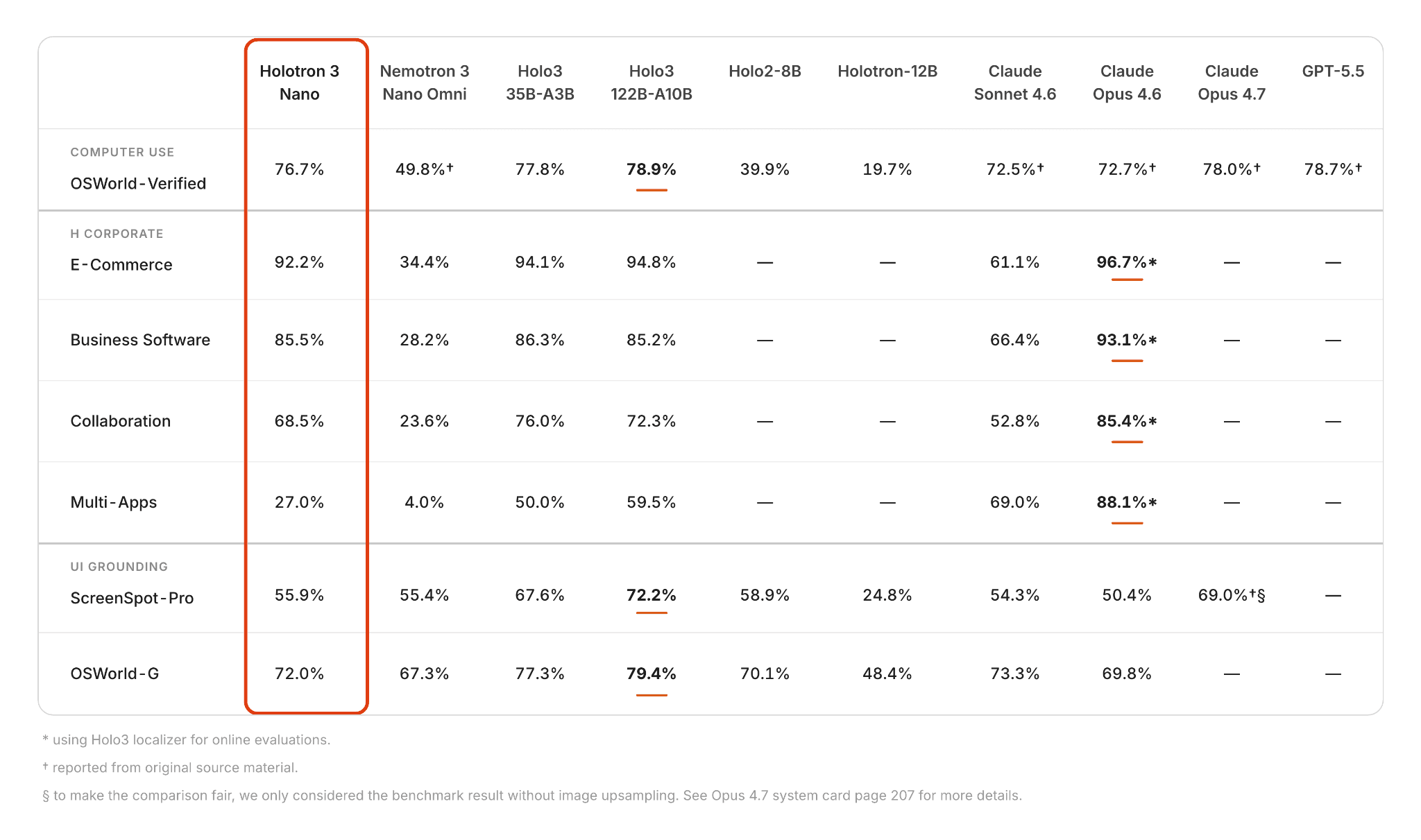
On OSWorld-Verified, Holotron 3 Nano achieves an impressive score of 76.7%, compared to Nemotron 3 Nano Omni (49.8%), matching frontier models like Claude Sonnet 4.7 (78.0%) and GPT-5.5 (78.7%) at a fraction of the cost. This reflects substantially improved reliability in end-to-end task completion.
Built on Nemotron 3 Nano Omni, an efficient foundation optimized for high throughput, low latency, and cost efficiency, Holotron 3 Nano applies targeted post-training to deliver strong accuracy gains for agentic applications across domains in our internal enterprise benchmarks:
E-Commerce: 92.2% vs 34.4%
Business Software: 85.5% vs 28.6%
Collaboration: 68.5% vs 23.6%
Multi-App workflows: 27.0% vs 3.97%
While still trailing the strongest proprietary models in some categories, Holotron 3 Nano narrows the gap substantially and demonstrates robust generalization across application environments.
On UI grounding and localization, Holotron 3 Nano also improves over the base model:
ScreenSpot-Pro: 55.9% (vs 55.4%, roughly on par)
OSWorld-G: 72.0% (vs 67.3%)
These results indicate stronger visual grounding and interaction accuracy, particularly in tasks requiring alignment between perception and action.
Overall, the gains are most significant in multi-step, cross-application tasks, where longer context handling and improved reasoning lead to more reliable execution trajectories.
Holotron 3 in HoloTab
Holotron 3 Nano is now live in HoloTab alongside Holo 3 Flash, and the speedup is noticeable. Mean per-step LLM latency drops from 2.0s to 1.7s, a 15% reduction in the time the agent spends "thinking" between actions. Those savings compound on long, multi-step tasks, shortening full trajectories end-to-end. Head over to HoloTab to see how it feels in practice!
Conclusion
Holotron 3 Nano represents a powerful synthesis of the highly efficient open NVIDIA Nemotron 3 Omni model and H Company’s specialized expertise in agentic workflows. By post-training this foundation on 52 billion tokens of our proprietary data, we have tailored its Sparse hybrid Mamba-MoE for the demands and complexities of computer-use tasks.
This model proves that high-capacity reasoning does not require a trade-off in speed. By integrating the efficient active-parameter footprint of the Nemotron 3 Nano Omni architecture with our C-RADIOv4 vision encoder, we have created a model that outperforms its predecessors. With native 256K token context support and industry-leading throughput, Holotron 3 Nano establishes a new Pareto frontier for the price-performance of enterprise agents.
The model and checkpoints are available now on Hugging Face under the NVIDIA Open Model License.
What's Next?
We see Holotron 3 Nano as the first in a new family of high-performance models. As NVIDIA expands the Nemotron 3 family of models with Super and Ultra variants, we intend to post-train these next-generation backbones to optimize their performance on computer use. Our roadmap focuses on evolving our training stack for greater efficiency and refining our data mixtures. Combined with multi-environment reinforcement learning, these advancements ensure we deliver the most reliable, high-throughput computer-use agents at enterprise scale.
To go further, check NVIDIA technical blog.