
Holo3.1
June 1st, 2026
Holo3.1: Computer Use from Edge to Cloud
Today we are releasing Holo3.1, the next generation of our computer-use model family.
Holo3.1 builds on the foundation established by Holo3: state-of-the-art computer-use performance with enterprise-ready agent capabilities. But raw capability is only half the story. As computer-use agents move from experimentation to production, organizations need models that can run wherever their workflows live: in the cloud, on dedicated inference appliances, or directly on end-user devices.
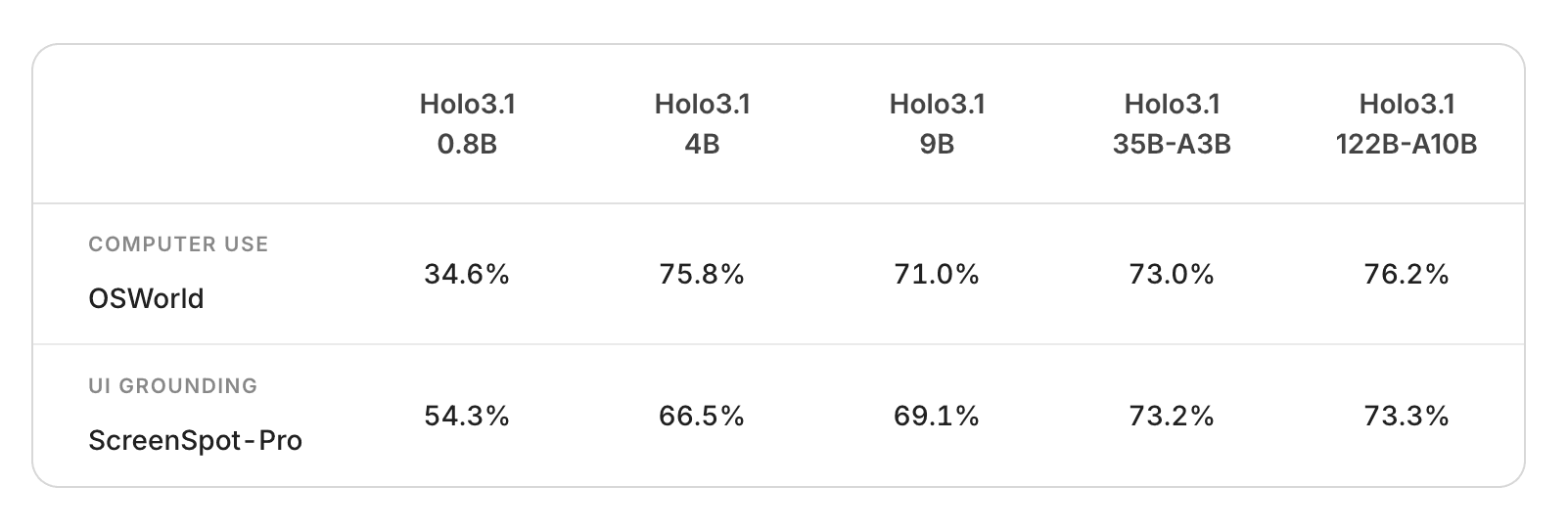
This is why the Holo3.1 family spans model sizes from 0.8B to 122B parameters, enabling everything from lightweight on-device agents to state-of-the-art enterprise deployments.
For the first time, we are also releasing quantized checkpoints optimized for local inference, including FP8, Q4 GGUF, and NVFP4 variants for selected checkpoints in the Holo3.1 family. We worked with NVIDIA on agent-harness optimizations that, combined with NVFP4 quantization, make the agent roughly 2× faster end-to-end on DGX Spark, while Q4 GGUF checkpoints bring the Computer Use Agent to consumer hardware like Apple Silicon.
This is a major step toward our vision of universal computer-use agents: systems that can operate across any application, on any device, in any environment.
One Family, 0.8B to 122B
The Holo3.1 family is based on the Qwen 3.5 & 3.6 family and spans small models (0.8B, 4B, 9B) for cost-effective and private on-device inference, and larger models (35B-A3B and 122B-A10B) for state-of-the-art performance.
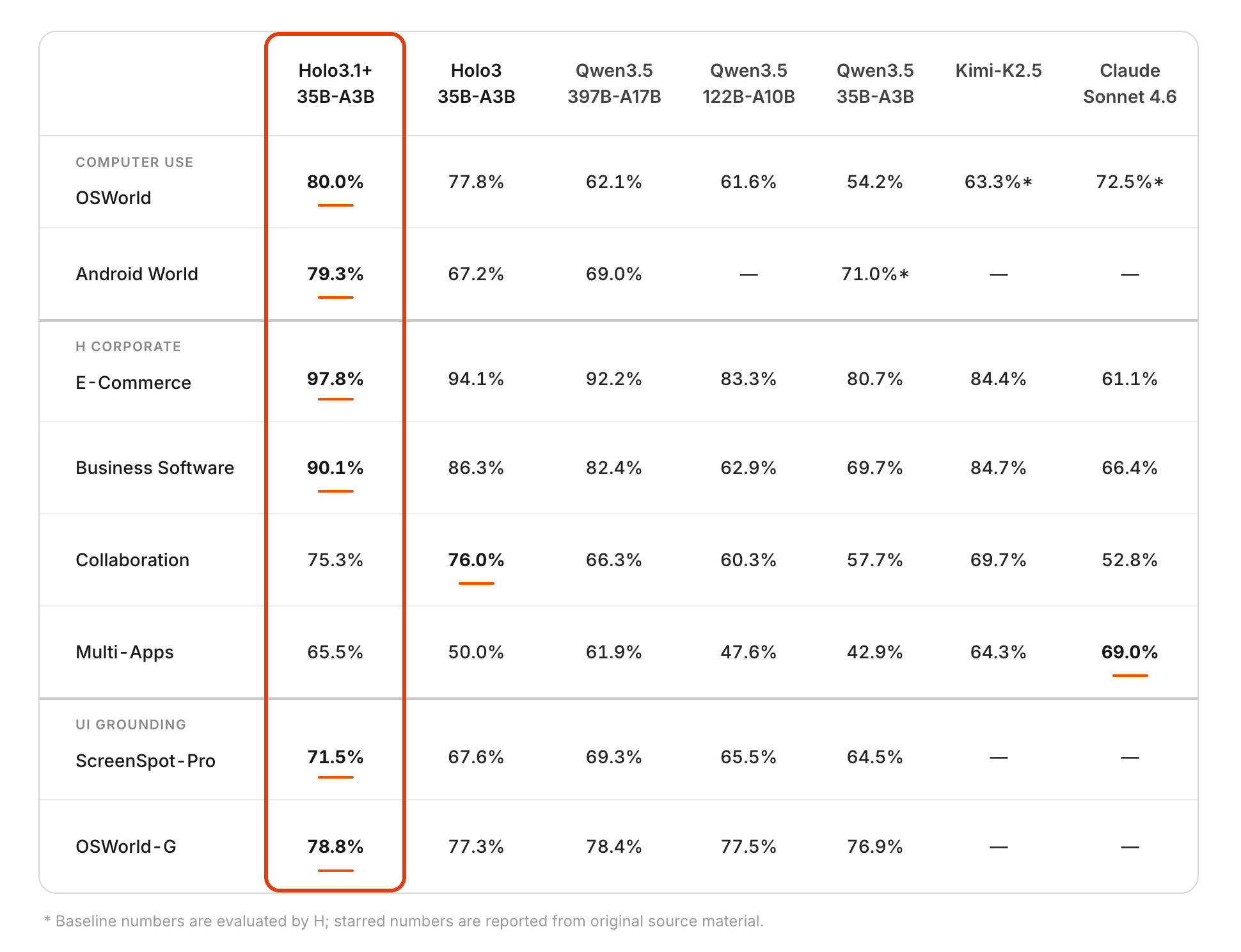
For the 35B-A3B variant, we introduced a novel synthesis framework designed to unify the distinct architectural strengths of the Holo lineage. Harmonizing the generalization capabilities of Holo3.1 with the computer-use excellence of Holo3 achieves a compounding effect. For this size, we introduce Holo3.1+ 35B-A3B, which shows a marked performance gain over Holo3.1 35B-A3B.
Beyond the Desktop: Mobile and Cross-Harness
Holo3.1 expands Holo3’s capabilities beyond browser and desktop control, delivering massive gains on mobile. On AndroidWorld, our 35B-A3B model’s performance jumped from 67% to 79.3%, while the smaller 4B and 9B sizes saw a leap from 58% to 71%.
To better support teams running our models inside third-party agent frameworks, Holo3.1 introduces native support for function-calling protocols, expanding on the JSON structured outputs native to Holo3. On OSWorld and on our internal benchmark suite (E-Commerce, Business Software and Collaboration Software), the two modes now reach parity. Holo3.1 also outperforms Holo3 by more than 25% when used within our Holotab product harness.
Fast Local Inference for Computer Use Agents
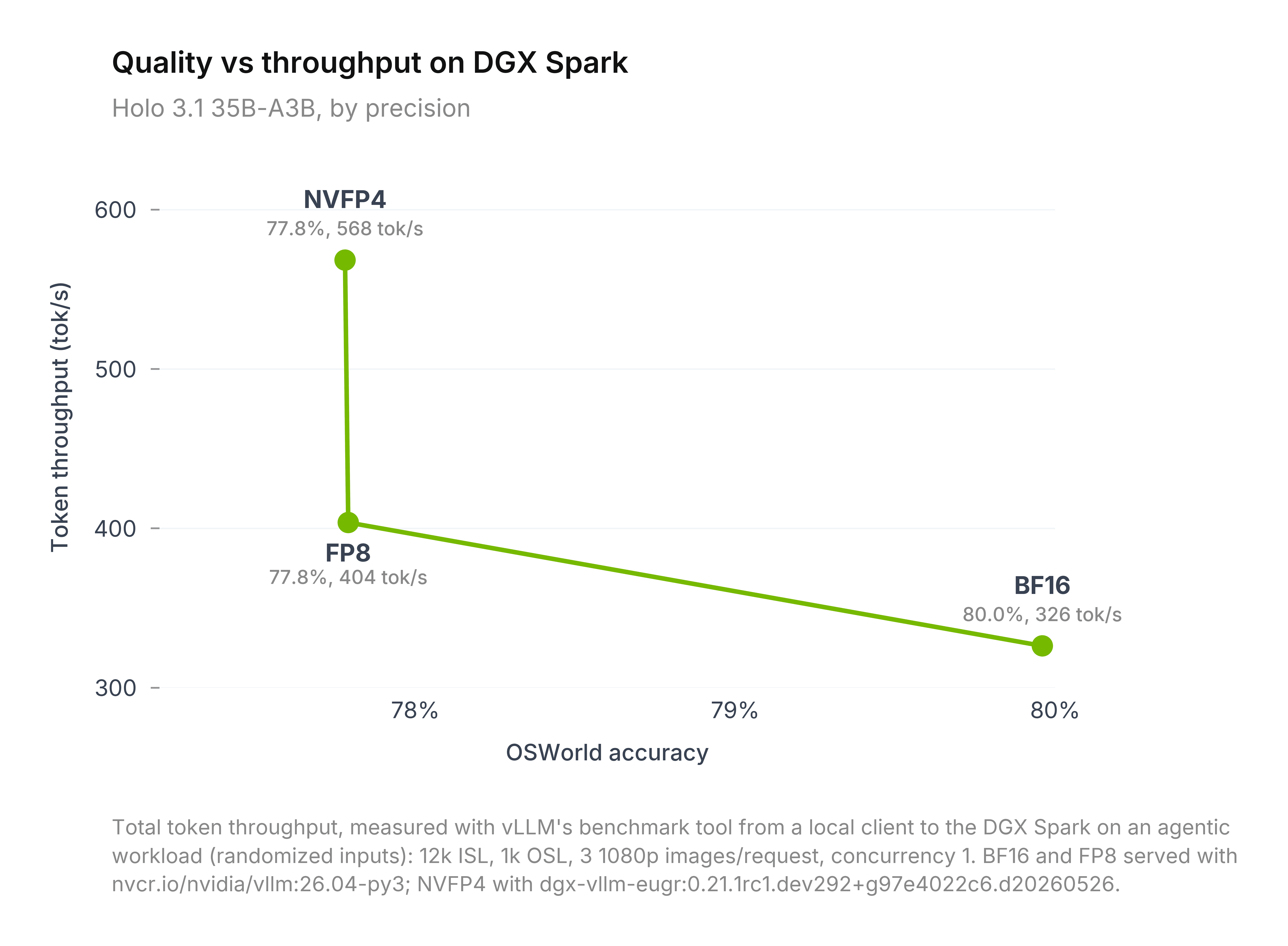
This is our first release to ship quantized weights. We’re starting with 35B-A3B checkpoints, available in FP8, Q4 GGUF, and NVFP4. For NVFP4, we used NVIDIA's Model Optimizer in a W4A16 configuration. These checkpoints enable fast local inference for Computer Use Agents with virtually no degradation in model performance. The speedups are substantial: on DGX Spark, NVFP4 W4A16 delivers 1.41× the total token throughput of FP8 and 1.74× that of BF16.
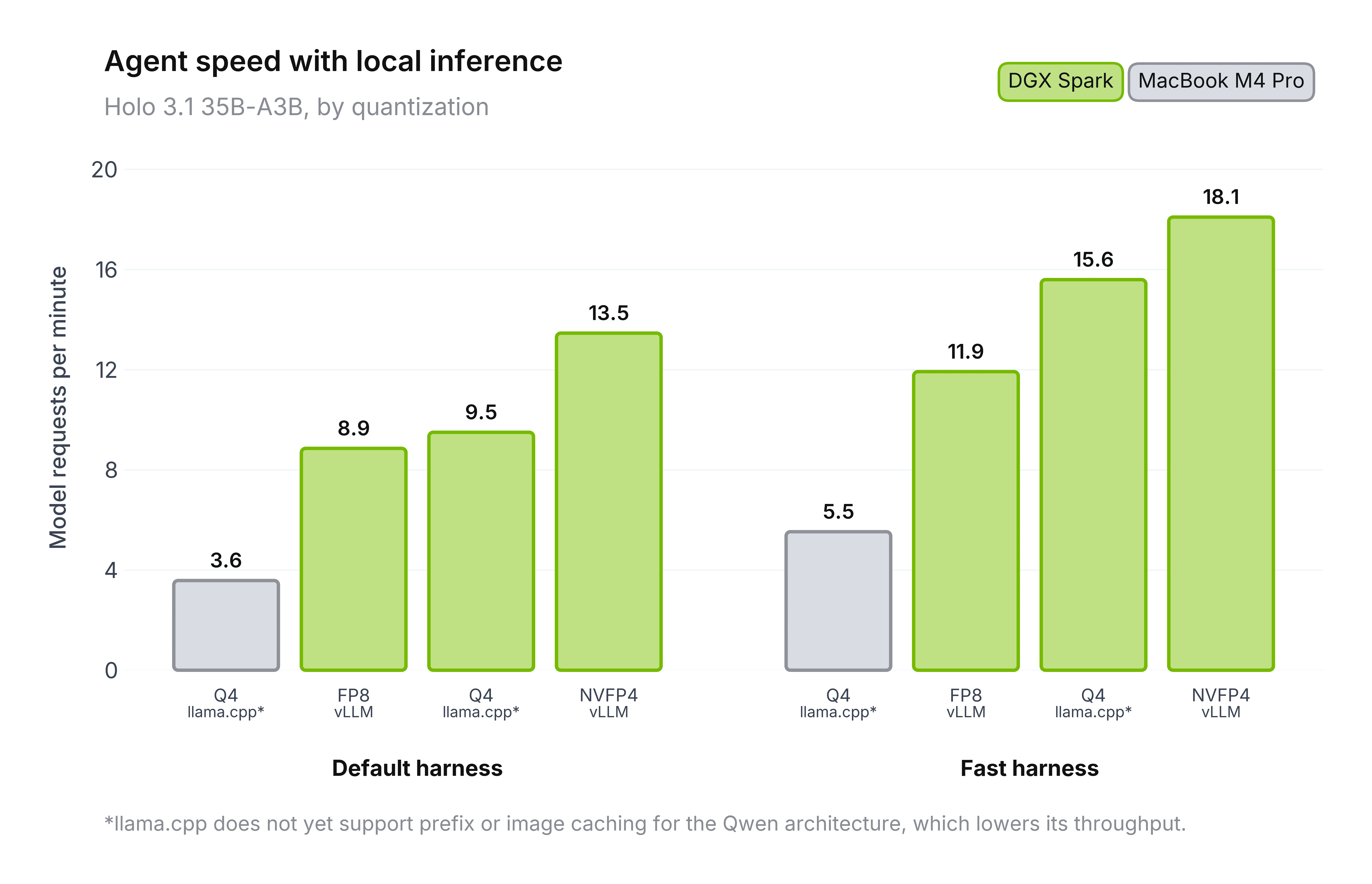
The Q4 GGUF checkpoints are aimed at local deployment of the Computer Use Agent on consumer hardware. The agent itself runs locally on a Windows or Mac machine, while the model can either run on that same machine - we include reference numbers for Apple Silicon - or on a DGX Spark on the same network. In both cases execution stays fully private and local, with nothing leaving the user's network. On Spark, agent-harness optimizations we developed with NVIDIA combined with the NVFP4 quantization above deliver a compound ~2× end-to-end speedup over the FP8 baseline, cutting average step time from 6.8s to 3.3s. The chart below shows agent request rate across platforms and precisions in two modes: on DGX Spark, vLLM with NVFP4 has the highest request rate in both Default and Fast modes, followed by Q4 GGUF and then FP8. These harness improvements and more will land in an upcoming desktop agent harness.
HoloDesktop: Your Private Computer-Use Agent
Code agents like Claude Code, Codex, Hermes, and Cursor reach the world through a terminal, but a lot of real work lives behind a GUI with no programmatic hook. This is why we are building HoloDesktop, an open-source desktop agent harness that lets Holo 3.1 act directly on your computer. It will plug in natively as a sub-agent: when a task needs to step out of the terminal and into a real application, your favorite coding agent delegates it to Holo. The result is a personal computer-use agent that runs wherever your work does: in the cloud through our Models API, or fully privately on your own machine with local inference we optimized together with NVIDIA. Coming soon.