
February 27, 2026
Learning from the user: GEO using computer-use agents vs. API limitations
By Antonio Ventura, Forward Deployed Engineer
Not long ago, a typical shopper’s journey started with a search box. A few keywords typed into Google, a scan through familiar blue links, and a handful of product pages opened for comparison. It was a predictable but slow process. These days, generative AI is changing that behavior. Customers are increasingly turning to conversational assistants such as ChatGPT and Perplexity to make recommendations, compare options, and explain trade-offs in a single response.
This behavioral shift is no longer anecdotal but reflected in industry forecasts: Salesforce forecasts that AI-driven traffic could generate 21% of global holiday orders¹, while Gartner predicts that by 2030, 20% of digital commerce transactions will be executed directly through AI platforms or agents², highlighting the rapid shift toward AI-mediated purchasing.
GEO (Generative Engine Optimization) matters because the interface now decides which products get seen, trusted, and bought. Yet many companies remain blind to how they appear inside these conversations and even further from understanding how to influence recommendation dynamics.
This makes it critical for companies to understand how AI conversational systems surface and prioritize products and to test them by authentically simulating how shoppers actually interact with live assistants.
In this research, we highlight a key insight: the same user request produces very different results depending on whether it’s made through an API or through a live LLM interface. We compare outputs from one of the most widely used interfaces, ChatGPT, with API-based responses to show how front-end interactions reshape what shoppers ultimately see.
Study objective
The experiment is about identifying the best way to simulate real human behavior when people use AI chatbots to look for product recommendations.
To test that, we compare ChatGPT Web UI and API web-search outputs under the same prompt conditions and ask a practical question: do these two paths produce comparable results, or do they diverge in meaningful ways (sources, products, and citations)?
The short version: they diverge. In this experiment, API and UI behaved like two different web research engines, with different retrieval behavior and meaningfully different evidence pools.
Preface: why OpenAI API results should differ from ChatGPT outputs
Unknown model layer – In ChatGPT, the exact model version or routing behind the interface may be abstracted, while API calls require explicitly selecting a model snapshot.
Hidden system prompts – The web interface includes secret built-in instructions that shape tone, structure, and safety behavior instructions.
User memory & personalization – ChatGPT can reference conversation history or saved memory, influencing answers in ways API requests won’t unless context is explicitly sent.
Interface-level tuning – Default parameters (like temperature, formatting style, and moderation layers) are preconfigured and hidden in ChatGPT.
Study setup
To understand how product recommendations change between API calls and the ChatGPT interface, we designed a simple but controlled experiment focused on three comparison layers: the products suggested, the sources cited, and the retrieval behavior behind them.
Scope – We focused only on product-related prompts, excluding services to keep comparisons consistent.
Prompt Set – 30 real-world shopping prompts designed to reflect how users actually ask AI what to buy.
Example prompt:
I need trail running shoes sold in Europe under EUR 190 for mixed terrain and wet conditions. Which models are best this season?
Multiple runs – Each prompt was executed several times on both the API and the web interface to capture variability.
Comparison dimensions
Product outputs: comparing the suggested products across runs to determine whether both methods surface the same recommendations.
Citations & sources: comparing the URLs referenced to evaluate whether both systems rely on the same websites when suggesting products.
Retrieval queries: analyzing the underlying search queries to see whether the two methods use similar retrieval strategies.
How we compare – Instead of showing every single run, results are consolidated into one row per prompt for easier analysis.
How consolidation works
Each prompt was executed multiple times, and results were consolidated across runs using consistent rules.
Top 3 products aggregated using majority voting, keeping the items that appeared most frequently as recommendations across responses.
URLs & Citations – all detected links were appended into a single combined list to capture the full range of retrieved sources, reflecting higher variability between runs.
Shopping-window items – merged across runs to represent the total exposure users would have seen.
Why majority voting was needed
Because of run-to-run variance, we use majority voting to stabilize product outputs:
Products are clustered with fuzzy matching.
Frequency across runs is counted.
The top 3 most recurring products are retained based on a Run Consistency Score, a pairwise Jaccard similarity averaged across runs.
This gives a more robust “consensus product set” per prompt than any single run.
Key results
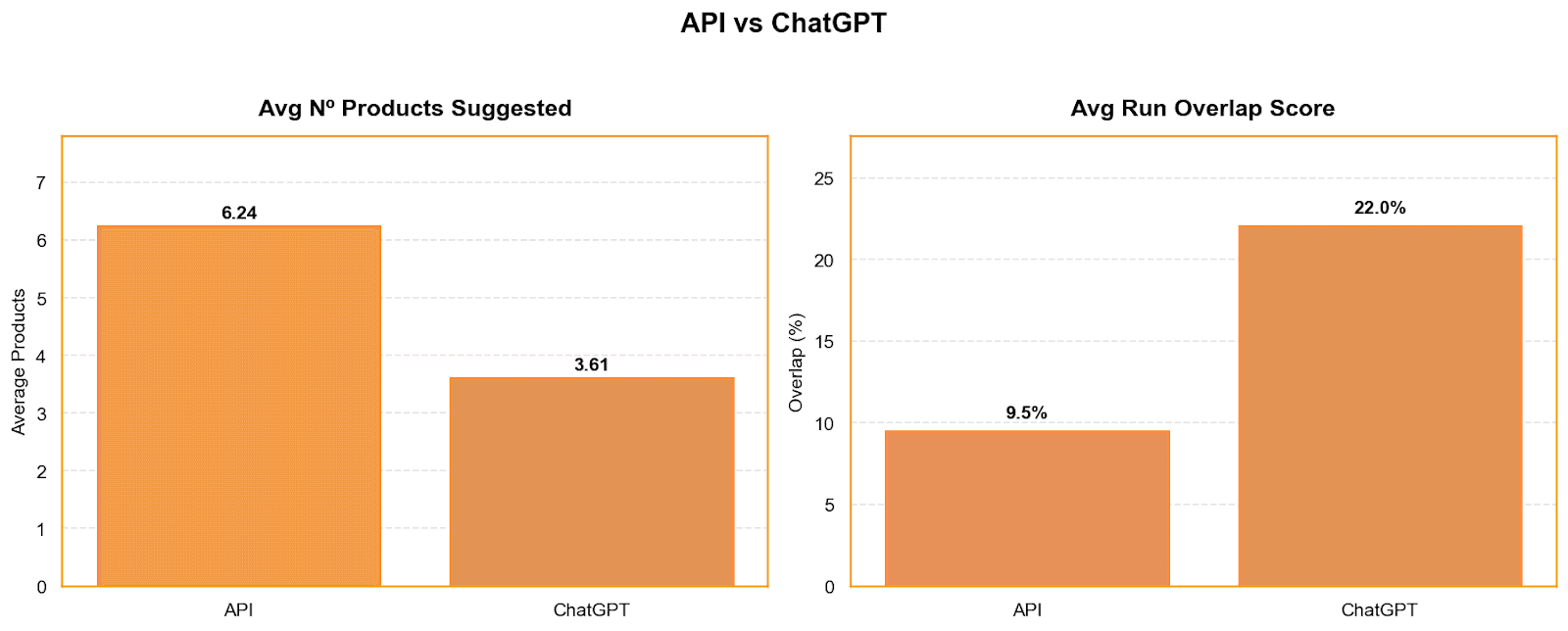
While overall answer length remains broadly similar between the API and the ChatGPT interface, the structure of recommendations differs significantly.
On average, the API surfaces far more products per prompt, recommending about 6.2 items compared to 3.6 in the Web UI. Despite being shorter lists, Web UI responses are noticeably more stable: under our Run Consistency Score, the interface reaches a score of 22, more than double the API’s 9. In practice, this means API outputs fluctuate more from run to run, while the UI tends to converge around a smaller, repeatable set of products.
The overlap between what the API and the Web UI recommend is low. Only about 18% of top products appearing in the interface also show up in API responses, fewer than one in five. The gap becomes even clearer when looking at evidence sources: the API includes roughly twice as many citation links, yet citation overlap is just ~2.5%, suggesting the two surfaces rely on largely different information pools.
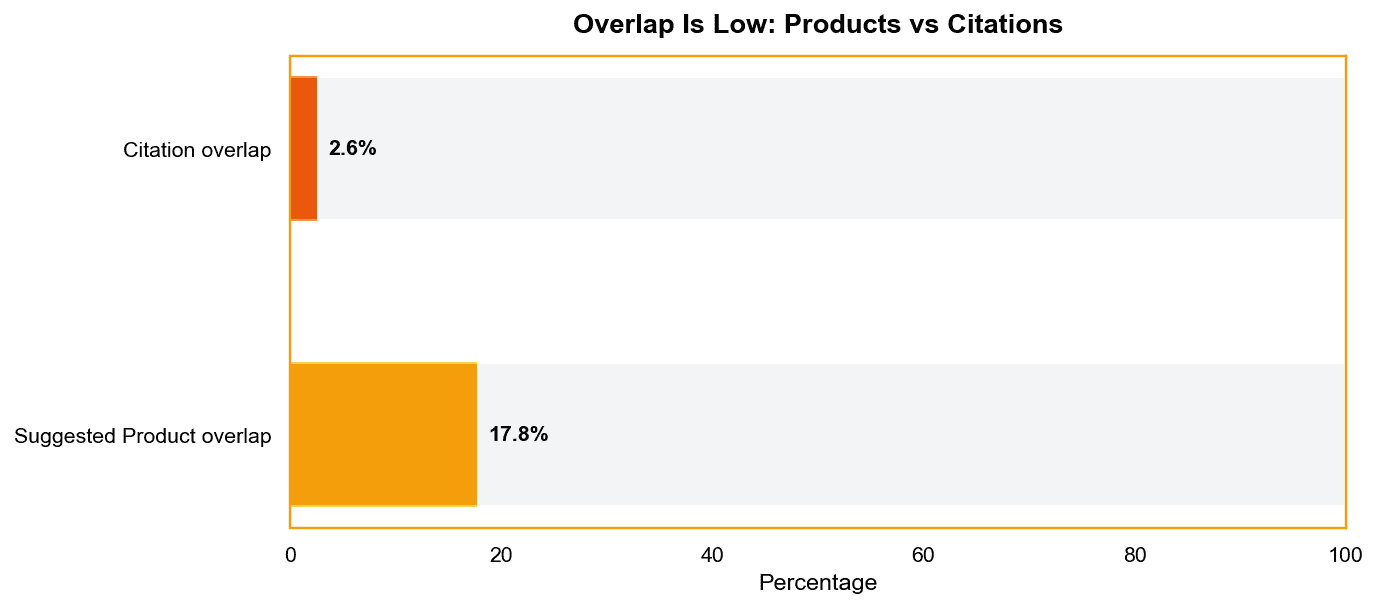
Finally, products shown in the Web UI’s shopping window rarely carry over into API outputs. Only about 13% of those items appear in API responses at all, even as simple mentions rather than recommendations, reinforcing how strongly the front-end experience shapes what shoppers actually see.
Citation study - where do recommendations get their evidence?
Understanding what products appear is only part of the analysis. In AI-driven shopping, the type of sources cited influences how recommendations are constructed and interpreted. Editorial content, brand-controlled pages, and community discussions represent different evidence layers, and shifts in this source mix can explain why two interfaces produce different outputs for the same prompt. Analyzing citation sources therefore helps clarify how each surface builds its recommendation set.
To analyze this, following Chen, Mahe, et al.³ we classify citation sources into three groups:
Brand: first-party or brand-controlled properties (official sites, brand stores, campaign pages).
Earned: third-party editorial or independent coverage (publishers, review sites, comparison guides).
Social: user-generated or community platforms (forums, social posts, creator discussions).
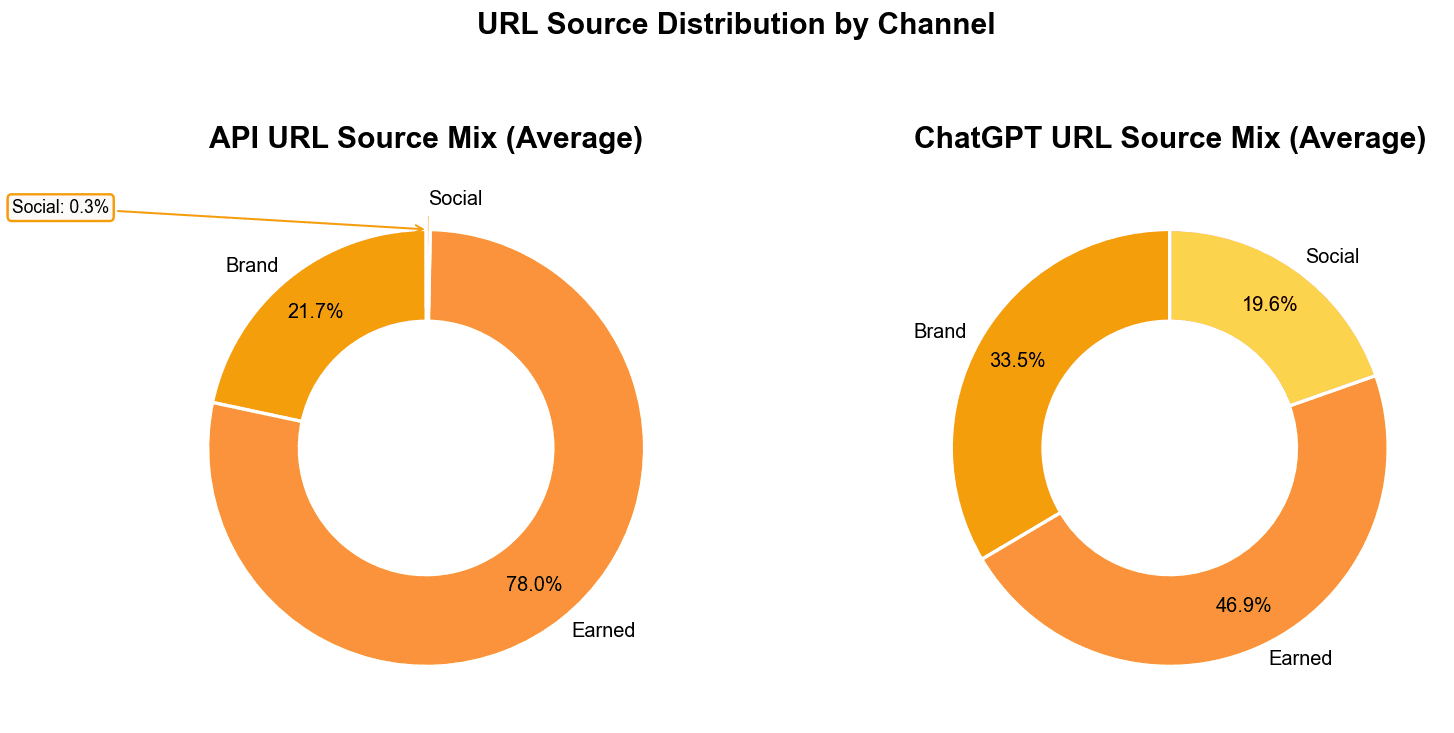
The API behaves like a strongly editorial-driven pipeline: nearly 78% of its evidence comes from earned sources, with almost no social presence. The Web UI, on the other hand, pulls from a broader mix, earned content remains dominant, but brand properties and social/community signals appear much more frequently.
Overall, these findings suggest that API outputs are not a reliable proxy for real consumer-facing experiences. The API recommends different products, retrieves largely distinct sources, and relies on divergent search queries compared to the live interface. As a result, research and optimization efforts should shift toward testing within front-end interfaces, where recommendations more accurately reflect what shoppers encounter and how decisions are shaped in real conversational environments.
Computer-use agents for measurable visibility and automatic implementation
At H, we approach AI search monitoring through direct interaction with live environments, where computer-use agents not only measure visibility dynamics but also execute targeted improvement strategies based on observed outcomes. We continuously observe real AI interfaces, including systems such as ChatGPT and Perplexity, to capture how brands and products are actually surfaced to end users. By interacting directly with front-end environments instead of relying solely on API outputs, our framework produces insights grounded in the same context real shoppers experience.
Our computer-use agents go far beyond passive GEO monitoring. They operate at scale, simulating large volumes of realistic user journeys to measure how recommendation patterns evolve over time. They actively navigate the product pages of top-performing recommendations, analyze why certain products rank higher, and turn those insights into concrete, practical improvements, either as clear action points or direct optimizations applied directly to the brand’s own pages.
At the same time, the agents act as “mystery shoppers,” simulating real customer journeys across websites to evaluate usability, visibility, and how products actually appear to a human visitor. This means brands can clearly see what works, what doesn’t, and what to change on their pages to improve both visibility in AI results and the actual shopping experience.
Start exploring AI visibility with H’s computer-use agent platform and understand how your brand is actually represented across generative interfaces. Our team works with you to deploy a measurement and optimization framework tailored to your industry, combining interface monitoring, GEO insights, and agent-driven improvement strategies. Move beyond static analytics and gain validated, real-world signals on how AI systems surface your products, contact us to see how H can help you actively shape your brand’s presence in AI-driven discovery.
References
[1] AI and Agents Present a $263B Holiday Opportunity for Retailers in 2025 - Salesforce
[2] Guseva, Irina. 2026. "Optimize Enterprise Apps for Agentic AI’s GEO and AEO." Gartner, January 7. ID G00841018.
[3] [2509.08919] Generative Engine Optimization: How to Dominate AI Search